[교차 검증]
교차 검증을 사용하는 가장 큰 이유는 과적합(Overfitting)을 막기 위함이다.
과적합은 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측을 다른 데이터로 수행할 경우 예측 성능이 과도하게 떨어지는 것을 말한다. 이런 문제점을 개선하기 위해 교차 검증을 활용한다.
즉 수능 보기 전 모의고사를 여러번 치루는 것.
교차 검증은 테스트 데이터 셋 이외의 검증 데이터 셋을 만들어 모델을 다양하게 훈련하고 평가하는 데 사용한다.
K-Fold 교차 검증
가장 보편적으로 사용되는 교차 검증 기법이다.
K개의 데이터 폴드 세트를 만들어 K번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하게 된다.
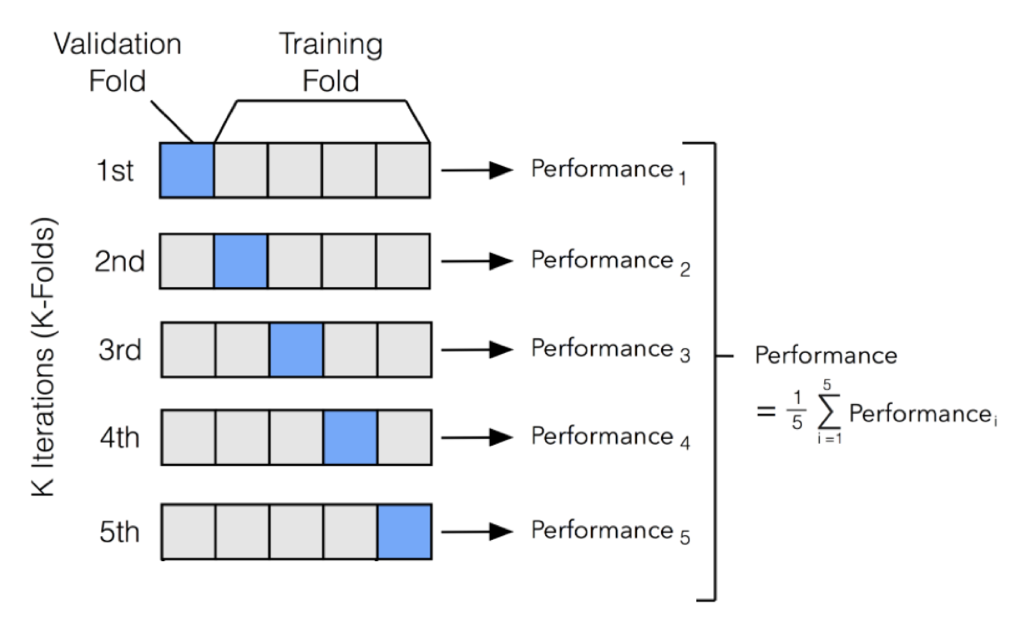
위 그림처럼 데이터 세트를 훈련 데이터, 검증 데이터를 점진적으로 5개로 나눠 학습과 검증 평가를 수행하는 것이다.
K-Fold 실습
kf = KFold(n_splits=5)
rf_nmse = []
n_iter = 0
rf = RandomForestRegressor()
for train_index, val_index in kf.split(X_train):
kf_X_train, kf_X_val = X_train.iloc[train_index, ], X_train.iloc[val_index, ]
kf_y_train, kf_y_val = y_train.iloc[train_index], y_train.iloc[val_index, ]
rf.fit(kf_X_train, kf_y_train)
pred = rf.predict(kf_X_val)
pred_train = rf.predict(kf_X_train)
train_mse = mean_squared_error(kf_y_train, pred_train)
val_mse = mean_squared_error(kf_y_val, pred)
train_rmse = np.sqrt(train_mse)
val_rmse = np.sqrt(val_mse)
n_iter += 1
rf_nmse.append(val_rmse)
print("{0} | VAL_RMSE {1} | TRAIN_RMSE {4} | 학습데이터 크기 {2} | 검증데이터 크기 {3}".format(n_iter, val_rmse, len(train_index), len(val_index), train_rmse))
print(sum(rf_nmse) / len(rf_nmse))
Stratified K-Fold 교차 검증
target 의 값들이 균등하게 분포하도록 하는 교차 검증 방법이다.
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold, StratifiedKFold
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns = iris.feature_names)
iris_df['label'] = iris.target
iris_df['label'].value_counts()
kfold = KFold(n_splits=3)
n_iter = 0
for train_index, val_index in kfold.split(iris_df):
n_iter += 1
label_train = iris_df['label'].iloc[train_index]
label_val = iris_df['label'].iloc[val_index]
print("교차 검증 {0}".format(n_iter))
print("훈련 데이터 라벨 분포")
print(label_train.value_counts())
print("검증 데이터 라벨 분포")
print(label_val.value_counts())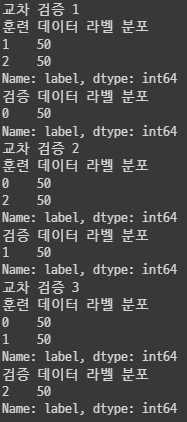
결과를 보면 레이블 분포가 골고루 분포되어 있지 않다.
교차 검증 1의 상황을 보면 훈련데이터는 1, 2 라벨만 훈련하게 되고 검증 데이터는 0 라벨을 테스트하게 된다. 이는 하나도 맞추지 못할 것이다.
이때 StratifiedKFold 로 라벨 분포를 맞춰주게 된다.
skf = StratifiedKFold(n_splits=3)
n_iter = 0
for train_index, val_index in skf.split(iris_df, iris_df['label']):
n_iter += 1
label_train = iris_df['label'].iloc[train_index]
label_val = iris_df['label'].iloc[val_index]
print("교차 검증 {0}".format(n_iter))
print("훈련 데이터 라벨 분포")
print(label_train.value_counts())
print("검증 데이터 라벨 분포")
print(label_val.value_counts())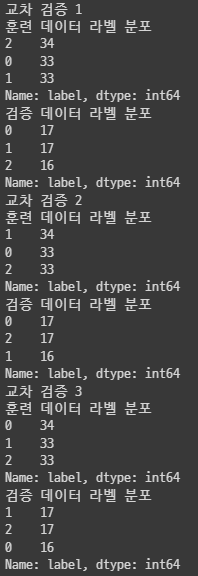
결과를 보면 훈련, 검증 데이터 라벨 분포가 일정하게 되어 있는 것을 알 수 있다.
일반적으로 분류 문제에선 Stratified K-Fold를 이용하고 회귀에서는 K-Fold를 이용한다.
회귀의 결정값은 이산값의 형태가 아니라 연속된 숫자값이기 때문에 결정값별로 분포를 정하는 의미가 없기 때문이다.
교차 검증을 편리하게 cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
import numpy as np
dt = DecisionTreeClassifier()
X = iris_df.drop('label', axis=1)
y = iris_df['label']
scores = cross_val_score(dt, X, y, scoring = 'accuracy', cv=5)
print('교차 검증별 정확도 :', np.round(scores, 4))
print("평균 검증 정확도 :", np.round(np.mean(scores), 4))
cross_val_score는 모델이 회귀냐 분류냐에 따라 K-Fold를 일반으로 할지, Stratified 로 할지 자동으로 적용한다.
'AI' 카테고리의 다른 글
| 단순 논리 회로 (1) | 2023.10.10 |
|---|---|
| [인공지능 학습 HUB] (0) | 2023.10.10 |
| GridSearch - 교차 검증과 최적의 하이퍼 파리미터 찾기 (0) | 2022.12.04 |
| [글] 독립 변수, 종속 변수 (feature, label) (0) | 2022.11.27 |
| [글] AI, 머신러닝, 딥러닝, 지도학습, 비지도학습 (0) | 2022.11.25 |